
摘要:
对关系的理解越深,洞察就越有力。有了足够多的关系数据点,你甚至可以预测未来。但是,随着关联的数据越多,关联数据的大小和复杂度就会增长,数据关系的存储和查询就会变得更复杂。为了更高效地处理数据间的关系,使用图数据库就是一个很好的选择。
正文:
你有没有接到过银行的电话,因为他们怀疑你有欺诈行为?当支付模式或地点偏离了常态时,大部分银行能够自动识别并立即行动。很多时候,这种情况发生在受害者还没有注意到损失之前。这样一来,身份盗窃行为严重影响一个人的银行账号和生活之前就可以得到有效处理。
只要对你的数据之间的联系有一个深刻的理解,就可以像上述案例那样获得强大的能力。
考虑疾病和基因交互之间的关系。理解这些关系后,你就可以在蛋白质结构中寻找到与疾病有关的其它基因。这种信息有助于改进疾病研究工作。
对关系的理解越深,洞察就越有力。有了足够多的关系数据点,你甚至可以预测未来(比如使用推荐引擎)。但是,随着关联的数据越多,关联数据的大小和复杂度就会增长,数据关系的存储和查询就会变得更复杂。
8 月份,我写了一篇关于现代应用程序开发和将通用的单体数据库分解成专门用途的数据库的价值的文章。专门用途的数据库支持各种数据模型,允许客户构建用例驱动的、高扩展性的、分布式应用程序。挖掘数据关系是很好的例子,说明了为什么拥有合适的工具很重要。图数据库是处理高度关联的数据的绝佳工具。
图数据模型
在一个图数据模型中,关系是数据模型的核心部分,这意味着你可以直接创建一个关系,而不是使用外键或表关联来创建关系。数据用节点(顶点)和链接(边)建模。换句话说,焦点不是数据本身,而是数据间相互关联的方式。图是构建那些处理关系的应用程序的自然选择,因为你可以更容易地表示和遍历数据间的关系。
节点通常是一个人、地点或事物,而链接是他们是关联起来的方式。例如,在下图中,Bob 是一个节点,蒙娜丽莎画像是一个节点,卢浮宫也是一个节点。他们通过许多不同的关系关联在一起。例如,Bob 对蒙娜丽莎画像感兴趣,蒙娜丽莎画像位于卢浮宫,而卢浮宫是一个博物馆。这个示例图是一个知识图谱。它可以被用来帮助那些对蒙娜丽莎画像感兴趣的人发现卢浮宫中达芬奇的其它艺术作品。
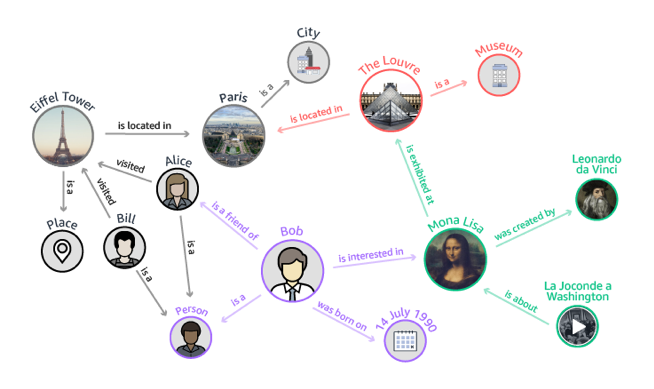
处理关系的应用程序
当你必须创建数据间的关系并快速查询这些关系的时候,图是一个不错的选择。知识图谱就是一个很好的用例。下面是一些其它示例:
社交网络
社交网络应用程序需要跟踪大量的用户简介和互动。例如,你可能正在为你的应用程序构建一个社交信息流。使用图来提供结果,按优先顺序显示来自家人、他们“喜欢”的朋友、他们附近的朋友的最新更新。
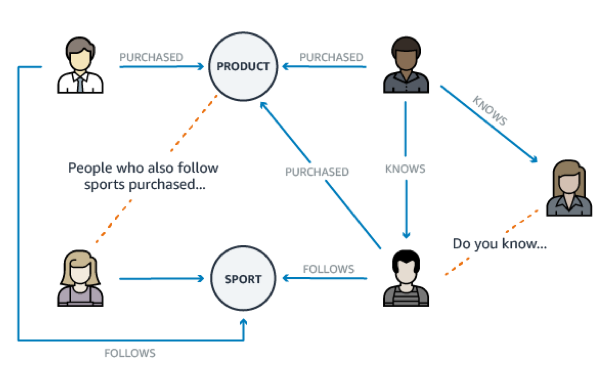
推荐引擎
推荐引擎存储信息之间的关系,例如客户兴趣、朋友和购买历史。通过图,你可以快速查询这些关系,并为你的用户提供个性化的关联推荐。
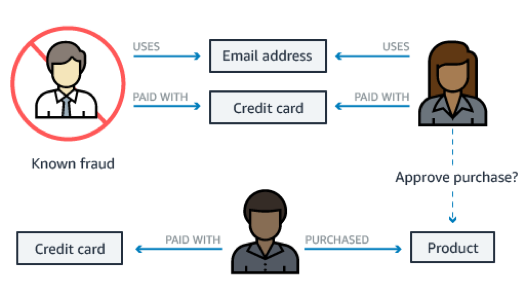
欺诈检测
如果你正在构建一个零售欺诈检测应用程序,图可以帮助你构建能够轻易检测关系模式的查询。例如,许多人关联到一个私人邮箱地址,或者许多人共享同一个 IP 地址但居住在不同的物理位置。
图存储的挑战
图可以用许多不同的方式存储:可以是一个关系数据库、键值对存储或者图数据库。许多人从一个小规模的原型开始使用图。这样做在一开始一般是没问题的,但是随着数据规模的增长会开始具有挑战性。基于图的工作负载通常具有很高的随机访问性。当你遍历关系时,访问的节点数量会显著增加,而且响应图查询所需的数据通常不会缓存在内存中(非本地)。
使用关系数据库或键值对存储图的人必须使用 SQL 关联(或类似手段)来查询关系。由于关联执行很慢,因此他们往往必须对其数据模型进行非规范化(换句话说,就是以牺牲写入性能的代价来提升读取性能)。然而,使用非规范化的数据模型,每个新增的关系都需要数据模型变更,并减缓开发的节奏。
图数据库是专门用来存储图的,允许节点上的数据直接关联并且可以直接查询关系。这使我们很容易创建新关系,而不用对数据进行非规范化;对于开发者而言,针对必须查询高度关联数据的应用程序时,更新他们的数据模型会更容易。它极大提升了数据关系的查询性能。
专门用途的图数据库
去年 ,AWS 发布了 Amazon Neptune ,一个快速的、可靠的、专门用途的图数据库,针对处理高度关联的数据间建立的关系进行了优化。Neptune 是一个完全托管的图服务,通过将你的数据复制到跨越三个可用性区域的六份副本来提供高可用性。它支持通过多达 15 个低延迟的读取副本来以毫秒级延迟查询图,以及通过自动化扩容来存储十亿级数据关联。
自从 Neptune 发布以来,我们仍在不断创新。上周,在 AWS 2019 创新回顾的发布会上,我们发布了Amazon Neptune Workbench 。现在你可以从 AWS 管理控制台创建一个 Jupyter 笔记本,这是一个开源 web 应用程序,允许你创建和分享包含在线代码、方程式、可视化和叙述性文本的文档。一旦创建了这个笔记本,你就可以使用 Gremlin 或 SPARQL Protocol 和 RDF 查询语言(SPARQL)查询图数据库。Neptune 最近新增了对 Streams 和 Search 的支持,使得它更容易使用其它应用程序构建块连接到你的图。 Neptune Streams 提供了一种简单的方法来获取你的图中的变化,而且可以与其它专用数据库集成。由于文本搜索是这项工作的合适工具,因此 Neptune 现在允许你在 Gremlin 或 SPARQL 图查询中使用外部文本索引。
看着我们的用户如何使用 Neptune 是非常有成就感的。我们期望他们使用 Neptune 构建社交、欺诈检测和推荐类型的解决方案,而像耐克、Activision 和 NBC Universal 这样的客户如今也在 Neptune 使用这些应用程序进行生产用途。
然而,当你向开发者提供针对特定工作的高性能专业工具时,就会发生比较有意思的事情,他们开始构建新的更令人兴奋的事物。从知识图谱到身份解析,客户已经表明他们可以使用图来构建有趣的新应用程序。Thomson Reuters 正在使用图来理解复杂的监管模式。Netflix 通过使用基于图的系统来构建和扩展数据沿袭,从而提高数据基础设施的可靠性。Zeta Global 已经构建了一个客户智能平台,使用基于图的身份解析来关联各种设备和用户。
长远视角:两种模型支持
我们已经知道,图是对关系建模的高效方法,分析关系的价值并不新鲜。事实上,网络数据库出现得比关系型数据库更早。图数据库早期大部分被应用在学术性或公共部门的一些应用程序,这些应用程序是面向研究的或者高度专业化的(例如语义数据管理或复杂的电信分析)。然而,这些解决方案并不是普适的,而且图数据库还没有成为开发者的一个主流数据库选项。
因此,我们期望 Neptune 成为一些客户的一项重要服务。从长远来看,我们认为使用数据关系的应用程序是一种战略,因此随着客户的数据以及数据间的关联增多,客户将会逐渐采用它。
作为这种长期视角的一个例子,在实现图时有两种模型——属性图(property graphs,PG)和 W3C资源描述框架(RDF)。这两种图都包含节点(有时称为“顶点”)和直接相连的边(有时称为“连接”)。两种图都允许 properties(attribute/value 对)与节点关联。属性图还允许属性与边关联,而 RDF 图将节点属性当做更简单的边(尽管在 RDF 中有集中表示边属性的技术)。由于这种差异,各图中的数据模型最终看起来略有不同。
这些差异存在的原因是很充分的。属性图类似于独立应用程序或用例中的传统数据结构,而 RDF 图最初是为了支持独立开发的应用程序之间的互操作性和数据交换而开发的。TDF 图可以表示为“三元组”(边缘起点、标签和终点——通常称为“subject”、“predicate”和“object”),而且 RDF 图数据库也被称为“三元组存储”。
如今,属性图已经在流行的开源和厂商支持的实现中可用,而对于模式定义、查询语言和数据交换格式还没有开放的标准。另一方面,RDF 是 W3C 标准化规范的一部分,它建立在其它现有的 web 标准之上。那些标准统称为语义化 Web 或链接数据。那些规范包括模式语言(RDF 和 OWL)、一种声明式查询语言(SPARQL)、序列化格式和大量支持规范(例如,如何将关系型数据库映射到 RDF 图)。W3C 规范还描述了一个标准化的推理框架(例如,如何从图形式的数据中得出结论)。
我们发现,开发者最终只想做图,而且他们需要这两种模型。我们看到,客户一开始用属性图开发一个独立的应用程序,但是之后发现他们必须与其他系统进行交互。我们看到,为了互操作性和数据交换而用 RDF 构建的用户,随后必须使用属性图中的数据来构建独立的特定业务的应用程序。我们对 Neptune 做了一个明确的选择,那就是同时支持属性图和 RDF,因此您可以选择最适合您的方案。
总结
我们的客户使用 Neptune 的创新方式就是 " 开发人员拥有适合他们的工具时会发生什么 " 的很好例子。AWS 之所以在云供应商中拥有最多的专用数据库,就是为了让客户拥有更多选择和自由。除了图,你可能还需要在其它不同数据类型有更好效果的数据集,例如关系型、时间序列型或内存型。这也很好——这就是现代应用程序开发。
例如,Neptune 是我们用来持续扩展 Alexa 的成百上千万的客户的知识图谱的工具之一。Alexa 还使用其它数据库,例如 Amazon DynamoDB 针对键值对数据和文档数据, Amazon Aurora 针对关系型数据。不同类型的数据带来不同类型的挑战,而为每一种用例选择正确的数据库可以获得更大的速度和灵活性。
对于高度关联的数据,图数据库可以使得理解数据中的关系更简单,从而获得新的见解。使用图数据模型,开发者可以快速构建必须查询高度关联数据的应用程序。而且专用图数据库能够明显提升关系的查询性能。因为开发人员最终都只想做图,你可以选择对属性图执行快速 Apache TinkerPop Gremlin 遍历,或者在 RDF 图上调整 SPARQL 查询。另外,你可以访问架构指南、代码示例和样例。
想了解更多关于如何利用数据中关系的信息,请参见 Amazon Neptune 。
作者介绍:
Werner Vogels 是 Amazon.com 的 CTO。
查看原文: The power of relationships in data

